
FreeFlyingSheep
Monday, March 9, 2026 | 3 分钟
股票分析 Demo
AI 学习笔记系列的第十篇,介绍了自己搭建的一个股票分析 Demo 全栈工程,分享了技术选型、设计思路、开发流程、已知问题和开发心得等内容。
Demo 目标和架构
这个 Demo 更像一个能长期维护的 Agent 系统,目标是把 A 股分析链路拆成稳定的工程模块,然后让 Agent 在可控流程里做决策和调用。
Docker Compose 架构图如下:

项目代码已经开源到 GitHub 仓库。 更具体的细节可以参考技术文档,这里主要介绍一些设计思路和技术选型的权衡。
技术选型
PostgreSQL
- 主要承担:
- 股票、分析、聊天、任务等结构化数据存储
- 向量检索(
pgvector)与全文检索(pg_textsearch)、中文搜索(zhparser)同库协同
- 替代品:
- MySQL(关系型数据库)
- Milvus(向量数据库)
- Elasticsearch(全文与检索增强)
- 选择原因:
- 这个项目里事务数据和检索数据可以先放在一套存储里,部署和维护成本更低
- 与
PgQueuer直接配合,任务队列不需要额外引入中间件 - 任务规模和查询负载在可控范围内,
pgvector性能足够
Redis
- 主要承担:
- 缓存
- 分布式锁
- SSE token 缓冲与 PubSub 推送
- 替代品:
- etcd / ZooKeeper(分布式锁)
- Kafka / RabbitMQ(消息队列)
- 选择原因:
- 多套功能需求都能用 Redis 解决,减少系统组件数量
- 聊天流式链路对低延迟缓存和发布订阅依赖强,Redis 工程实现简单、生态成熟
MinIO
- 主要承担:
- 原始财报 PDF 与处理产物对象存储
- 替代品:
- AWS S3
- 本地文件系统
- 选择原因:
- S3 兼容接口,本地开发和生产迁移路径清晰
- 本地文件系统不适合长期存储和分布式访问,MinIO 轻量级又易于部署
pgvector
- 主要承担:
- 报告分块向量字段存储与相似度检索
- 替代品:
- Milvus 等专门向量数据库
- 选择原因:
- 先复用 PostgreSQL 能力,减少系统组件数量
- 与 BM25 混合检索在同一数据面内实现更直接
PgQueuer
- 主要承担:
- 抓取与分析任务异步化
- 重试、延时执行、批量调度
- 替代品:
- Celery + Redis / RabbitMQ
- Kafka
- 选择原因:
- 对现有 PostgreSQL 依赖复用充分,部署链路更轻
- 对当前任务规模足够,开发复杂度较低
实际开发流程
- 搭后端基础能力
- FastAPI 提供 API 接口
- SQLAlchemy Async 接 PostgreSQL
- 先落好股票相关 model、schema、service
- 把数据层跑通
- Alembic 管理数据库迁移
- CSV 导入基础股票数据
- 补齐初始化与迁移脚本
- 接入数据采集
- 对接 CNInfo 和 Yahoo Finance crawler
- 完成抓取、清洗、入库链路
- 引入异步任务
- 用 pgqueuer 跑 crawl / analyze / update 后台任务
- 做基础前端
- SvelteKit 搭股票页和聊天页
- 前端部分是纯 AI 开发(Vibe Coding + Spec-driven Development)
- 与后端 API 对接
- 增加实时能力
- 聊天接口接入 SSE
- 前端流式消费 token,实时更新输出
- 接入 Agent 与 MCP
- LLM 聊天能力用于股票分析与解释
- LangGraph 编排 Agent 节点
- FastMCP 暴露 MCP server 给 Agent 调用工具
- 加缓存
- 用 Redis 缓存高频读取数据
- 同时用于聊天链路的缓冲与发布订阅
- 接入 RAG
- PDF 文本抽取
- chunk 切分、embedding、向量存储
- 检索结果回填给 Agent 生成回答
- 接可观测
- OpenTelemetry 打通 tracing、metrics、logging
- 指标、日志、链路统一看板化
- 做评估
- DeepEval 覆盖 RAG、chatbot、MCP、agent E2E、arena 式 LLM 对比
- 补质量门禁与交付
- pytest + testcontainers 做测试
- ruff、mypy 做代码质量检查
- GitHub Workflows 承载 CI
- Docker Compose / Kubernetes 负责部署
- 以上能力是在开发过程中持续迭代完善的,不是一次性完成
Agent 设计
Agent 流程图如下:
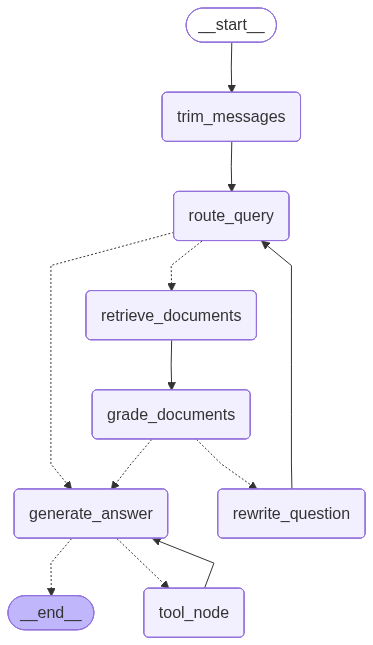
当前 Agent 由 LangGraph 状态图驱动,核心节点和职责如下:
trim_messages- 裁剪上下文,控制 token 成本和窗口占用
route_query- 判断走普通回答、工具调用还是检索增强
tool_node- 执行工具调用(通过 MCP 能力接入)
- 回填工具结果到上下文
retrieve_documents- 触发 RAG 检索,拉取候选证据块
grade_documents- 对候选块做相关性判断
- 决定是直接生成,还是继续改写问题再检索
rewrite_question- 对口语化或模糊问题做检索友好改写
generate_answer- 基于问题 + 证据 + 工具结果生成最终回答
流程上更接近 ReAct:
- 主流程:
- 接收输入
- 路由
- 工具调用 / 检索
- 结果评估
- 生成回答
- 保护机制:
- 对 chat / tool / retrieve 次数设上限,避免无限循环
- 文档不相关时触发重写分支,而不是盲目生成
RAG 设计
当前流程是:
- 离线 ingest:
- 从 MinIO
raw拉取 PDF - 文本抽取
- 分块(含 overlap)
- embedding
- 写入
report_chunks
- 从 MinIO
- 在线 query:
- 用户问题进入检索链路
- 并行做:
- 语义检索(向量)
- BM25 检索(关键词)
- 用 RRF 融合排序
- 返回候选块给 Agent 做后续生成
端到端流程
从数据进入系统到用户拿到回答,可以拆成下面这条多级流程:
- 数据准备
- 抓取股票与报告数据
- 原始文件入 MinIO
- 触发 ingest,生成向量与 BM25 索引
- 异步分析
update_stock_data拆分子任务- worker 执行
crawl/analyze任务 - 分析结果写回 PostgreSQL
- 在线问答
- 前端调用
/chat/start - 后端创建运行状态并启动后台生成
- 前端通过
/chat/stream持续接收 token 事件
- 前端调用
- Agent 执行
- route 判断是否需要工具和检索
- 需要时调用 MCP 工具与 RAG 检索
- 结果回填后生成答案并结束流
观测
观测链路目前包含:
- 应用侧埋点
- FastAPI
- HTTPX / requests
- SQLAlchemy / psycopg
- Redis
- LangChain
- 采集与转发(Alloy)
- traces -> Tempo + Langfuse
- logs -> Loki
- metrics -> Prometheus
- 展示与分析
- Grafana 看系统指标和链路健康
- Langfuse 看 Agent / LLM 调用细节
评估
离线评估采用 DeepEval,按能力分集执行:
chatbotllmagentmcprag
目前涉及的指标包括:
AnswerRelevancyMetricTaskCompletionMetricToolCorrectnessMetricArgumentCorrectnessMetricFaithfulnessMetric
已知问题
- 工具权限策略主要靠路由标签排除,缺少更细粒度权限模型
- RAG 的 chunk、融合参数、重排策略仍属于静态,不支持动态调整
- SSE 异常恢复与重放链路还需要更系统压测
- 暂无线上收集机制(例如真实用户 query、失败样本、人工反馈),离线评估集更新依赖人工维护
- 告警分级、响应流程和运行手册等还不完整
- 受硬件资源限制,只测试了单实例部署,K8s 组件不完善
- 在线(Github Workflows)只有 CI,没有 CD,部署仍需人工触发(没买服务器,没法做自动部署)
- 离线评估覆盖面和指标还比较有限,评估结果不够理想,主要问题在模型能力和 prompt 设计上
- 前端完全依赖 AI 生成,需要人工 review,必要时重构
开发心得
- AI 确实能显著提高开发效率。对小白来说,从零开始学习,到和 AI 互动理解概念,再到让 AI 辅助编程,1-2 个月内搭建一个完整工程化 demo 是可行的
- 一步一步搭建非常重要。先围绕具体需求做分析,再决定技术方案,尽可能减少不必要的依赖组件,而不是一开始把所有组件都接上
- 即使是小模型(例如 Qwen / Qwen3-8B),在接入 Agent 系统后效果也会有明显改善,但在复杂任务上仍然会显得比较“笨”,需要流程约束、工具和检索来兜底
- 真正困难的阶段通常不在把 demo 跑起来,而在后续维护升级,以及数据采集链路和质量的持续优化
- 拥抱 AI 技术是一个长期趋势。AI 在抬高大多数人能力下限的同时,也会进一步拉大人与人之间的差距。想把 AI 用好,前提仍然是持续提升自己的基础能力和工程判断力