
FreeFlyingSheep
Friday, July 24, 2020 | 9 分钟
连续页框的管理
Linux 内核学习笔记系列,内存管理部分,简单介绍连续页框的管理。
分区页框分配器
请求页框的标志
include/linux/gfp.h:
/*
* GFP bitmasks..
*/
/* Zone modifiers in GFP_ZONEMASK (see linux/mmzone.h - low two bits) */
#define __GFP_DMA 0x01
#define __GFP_HIGHMEM 0x02
/*
* Action modifiers - doesn't change the zoning
*
* __GFP_REPEAT: Try hard to allocate the memory, but the allocation attempt
* _might_ fail. This depends upon the particular VM implementation.
*
* __GFP_NOFAIL: The VM implementation _must_ retry infinitely: the caller
* cannot handle allocation failures.
*
* __GFP_NORETRY: The VM implementation must not retry indefinitely.
*/
#define __GFP_WAIT 0x10 /* Can wait and reschedule? */
#define __GFP_HIGH 0x20 /* Should access emergency pools? */
#define __GFP_IO 0x40 /* Can start physical IO? */
#define __GFP_FS 0x80 /* Can call down to low-level FS? */
#define __GFP_COLD 0x100 /* Cache-cold page required */
#define __GFP_NOWARN 0x200 /* Suppress page allocation failure warning */
#define __GFP_REPEAT 0x400 /* Retry the allocation. Might fail */
#define __GFP_NOFAIL 0x800 /* Retry for ever. Cannot fail */
#define __GFP_NORETRY 0x1000 /* Do not retry. Might fail */
#define __GFP_NO_GROW 0x2000 /* Slab internal usage */
#define __GFP_COMP 0x4000 /* Add compound page metadata */
#define __GFP_ZERO 0x8000 /* Return zeroed page on success */
#define __GFP_BITS_SHIFT 16 /* Room for 16 __GFP_FOO bits */
#define __GFP_BITS_MASK ((1 << __GFP_BITS_SHIFT) - 1)
/* if you forget to add the bitmask here kernel will crash, period */
#define GFP_LEVEL_MASK (__GFP_WAIT|__GFP_HIGH|__GFP_IO|__GFP_FS| \
__GFP_COLD|__GFP_NOWARN|__GFP_REPEAT| \
__GFP_NOFAIL|__GFP_NORETRY|__GFP_NO_GROW|__GFP_COMP)
#define GFP_ATOMIC (__GFP_HIGH)
#define GFP_NOIO (__GFP_WAIT)
#define GFP_NOFS (__GFP_WAIT | __GFP_IO)
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS)
#define GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HIGHMEM)
/* Flag - indicates that the buffer will be suitable for DMA. Ignored on some
platforms, used as appropriate on others */
#define GFP_DMA __GFP_DMA
请求页框
| 函数 | 功能 |
|---|---|
alloc_pages(gfp_mask, order) | 请求 2^order 个连续的页框,成功则返回分配的第一个页框描述符的地址,失败则返回 NULL。 |
alloc_page(gfp_mask) | 请求一个单独的页框,成功则返回分配的第一个页框描述符的地址,失败则返回 NULL。 |
__get_free_pages(gfp_mask, order) | 请求 2^order 个连续的页框,成功则返回分配的第一个页框的线性地址,失败则返回 0。 |
__get_free_page(gfp_mask) | 请求一个单独的页框,成功则返回分配的第一个页框的线性地址,失败则返回 0。 |
get_zeroed_page(gfp_mask) | 请求一个填满 0 的单独的页框,成功则返回分配的第一个页框的线性地址,失败则返回 0。 |
__get_dma_pages(gfp_mask, order) | 请求 2^order 个适用于 DMA 的页框,成功则返回分配的第一个页框的线性地址,失败则返回 0。 |
include/linux/gfp.h:
static inline struct page *alloc_pages_node(int nid, unsigned int gfp_mask,
unsigned int order)
{
if (unlikely(order >= MAX_ORDER))
return NULL;
return __alloc_pages(gfp_mask, order,
NODE_DATA(nid)->node_zonelists + (gfp_mask & GFP_ZONEMASK));
}
#ifdef CONFIG_NUMA
extern struct page *alloc_pages_current(unsigned gfp_mask, unsigned order);
static inline struct page *
alloc_pages(unsigned int gfp_mask, unsigned int order)
{
if (unlikely(order >= MAX_ORDER))
return NULL;
return alloc_pages_current(gfp_mask, order);
}
#else
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
#endif
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
extern unsigned long FASTCALL(__get_free_pages(unsigned int gfp_mask, unsigned int order));
extern unsigned long FASTCALL(get_zeroed_page(unsigned int gfp_mask));
#define __get_free_page(gfp_mask) \
__get_free_pages((gfp_mask),0)
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA,(order))
mm/page_alloc.c:
/*
* Common helper functions.
*/
fastcall unsigned long __get_free_pages(unsigned int gfp_mask, unsigned int order)
{
struct page * page;
page = alloc_pages(gfp_mask, order);
if (!page)
return 0;
return (unsigned long) page_address(page);
}
EXPORT_SYMBOL(__get_free_pages);
fastcall unsigned long get_zeroed_page(unsigned int gfp_mask)
{
struct page * page;
/*
* get_zeroed_page() returns a 32-bit address, which cannot represent
* a highmem page
*/
BUG_ON(gfp_mask & __GFP_HIGHMEM);
page = alloc_pages(gfp_mask | __GFP_ZERO, 0);
if (page)
return (unsigned long) page_address(page);
return 0;
}
EXPORT_SYMBOL(get_zeroed_page);
mm/mempolicy.c:
/**
* alloc_pages_current - Allocate pages.
*
* @gfp:
* %GFP_USER user allocation,
* %GFP_KERNEL kernel allocation,
* %GFP_HIGHMEM highmem allocation,
* %GFP_FS don't call back into a file system.
* %GFP_ATOMIC don't sleep.
* @order: Power of two of allocation size in pages. 0 is a single page.
*
* Allocate a page from the kernel page pool. When not in
* interrupt context and apply the current process NUMA policy.
* Returns NULL when no page can be allocated.
*/
struct page *alloc_pages_current(unsigned gfp, unsigned order)
{
struct mempolicy *pol = current->mempolicy;
if (!pol || in_interrupt())
pol = &default_policy;
if (pol->policy == MPOL_INTERLEAVE)
return alloc_page_interleave(gfp, order, interleave_nodes(pol));
return __alloc_pages(gfp, order, zonelist_policy(gfp, pol));
}
EXPORT_SYMBOL(alloc_pages_current);
__alloc_pages() 函数见 __alloc_pages() 函数。
释放页框
| 函数 | 功能 |
|---|---|
__free_pages(page, order) | 检查 page 指向的页描述符,若该页框未被保留 (PG_reserved 标志为 0),就把 count 减一。如果 count 为 0,就释放页框。 |
free_pages(addr, order) | 接受页框的线性地址而不是页描述符,其余和 __free_pages(page, order) 相同 |
__free_page(page) | __free_pages(page, 0) |
free_page(addr) | free_pages(addr, 0) |
include/linux/gfp.h:
extern void FASTCALL(__free_pages(struct page *page, unsigned int order));
extern void FASTCALL(free_pages(unsigned long addr, unsigned int order));
extern void FASTCALL(free_hot_page(struct page *page));
extern void FASTCALL(free_cold_page(struct page *page));
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr),0)
mm/page_alloc.c:
fastcall void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}
EXPORT_SYMBOL(free_pages);
__free_pages() 函数见释放内存。
很多函数涉及伙伴系统和 per-CPU 页框高速缓存,这里就不展开了。
管理区分配器简介
管理区分配器是内核页框分配器的前端。
整个连续内存分配涉及的内容大致如下:
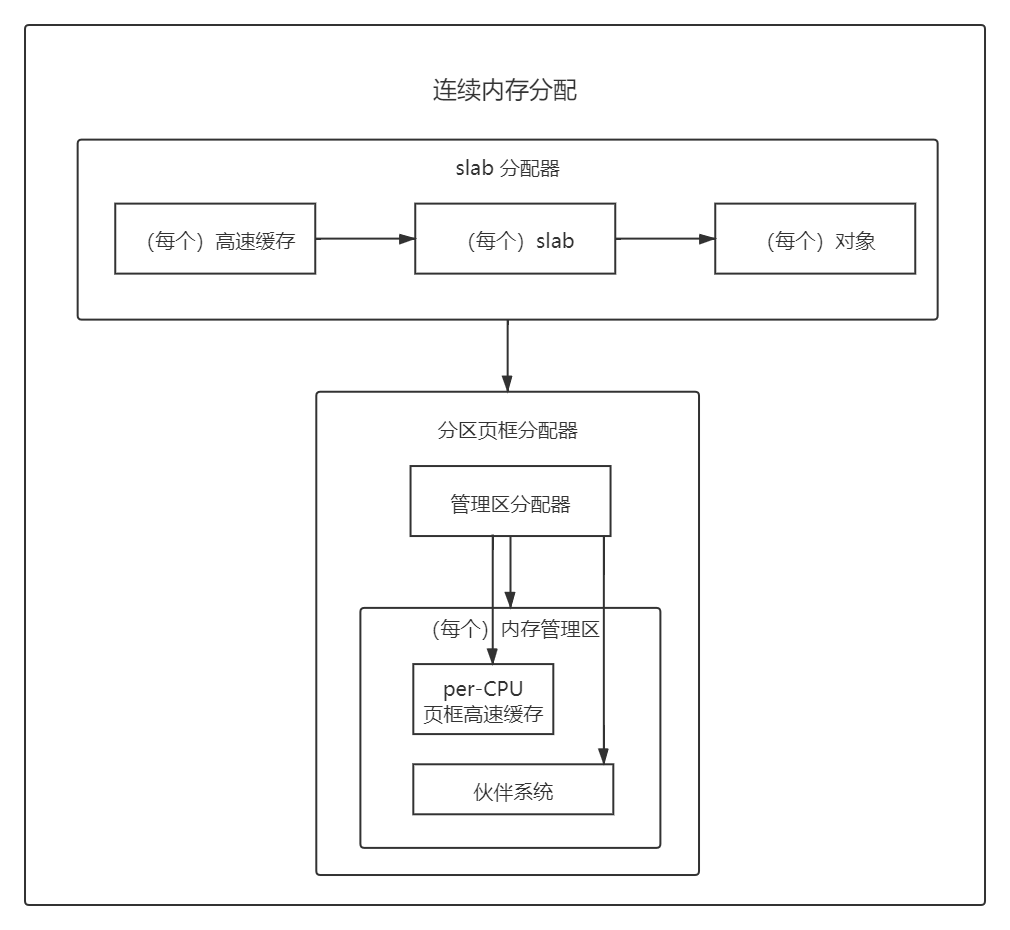
管理区分配器必须分配一个包含足够多空闲页框的内存区,来满足内存请求,它得满足如下目标:
- 保护保留的页框池。
- 当内存不足且允许阻塞当前进程时,应当触发页框回收算法,一旦某些页框被释放,将再次尝试分配。
- 如果可能,应当保存小而珍贵的
ZONE_DMA内存管理区。例如,如果是对ZONE_NORMAL或ZONE_HIGHMEM页框的请求,尽可能不分配ZONE_DMA内存管理区中的页框。
保留的页框池
在请求内存时,一些内核控制路径不能被阻塞,如处理中断或执行临界区内的代码时。在这些情况下,一条控制路径应当产生原子内存分配请求 (设置 GFP_ATOMIC 标志)。原子请求从不被阻塞,如果没有足够空闲页,仅返回失败。
尽管无法保证原子内存分配请求不失败,但内核会设法尽量减少这种不幸事件发生的可能性。因此,内核为原子内存分配请求保留了一个页框池,只有在内存不足时才使用。
保留内存的数量(以 KB 为单位)存放在 min_free_kbytes 变量中。管理区描述符的部分字段都会在 mim_free_kbytes 初始化时一起完成初始化(init_per_zone_pages_min() 函数调用 setup_per_zone_pages_min() 函数和 setup_per_zone_lowmem_reserve() 函数,这些函数都位于 mm/page_alloc.c)。
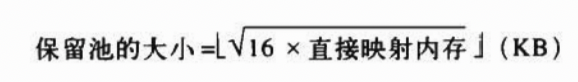
pages_min:管理区中保留页的数目,被设置如上图所示的大小。pages_low:回收页框使用的下界,被设置为pages_min的 5/4。pages_high:回收页框使用的上界,被设置为pages_min的 3/2。lowmem_reserve:每个管理区必须保留的页框数目,例子代码注释中有,见下。
/*
* results with 256, 32 in the lowmem_reserve sysctl:
* 1G machine -> (16M dma, 800M-16M normal, 1G-800M high)
* 1G machine -> (16M dma, 784M normal, 224M high)
* NORMAL allocation will leave 784M/256 of ram reserved in the ZONE_DMA
* HIGHMEM allocation will leave 224M/32 of ram reserved in ZONE_NORMAL
* HIGHMEM allocation will (224M+784M)/256 of ram reserved in ZONE_DMA
*/
分配内存
zone_watermark_ok() 函数
mm/page_alloc.c:
/*
* Return 1 if free pages are above 'mark'. This takes into account the order
* of the allocation.
*/
int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
int classzone_idx, int can_try_harder, int gfp_high)
{
/* free_pages my go negative - that's OK */
long min = mark, free_pages = z->free_pages - (1 << order) + 1;
int o;
if (gfp_high)
min -= min / 2;
if (can_try_harder)
min -= min / 4;
if (free_pages <= min + z->lowmem_reserve[classzone_idx])
return 0;
for (o = 0; o < order; o++) {
/* At the next order, this order's pages become unavailable */
free_pages -= z->free_area[o].nr_free << o;
/* Require fewer higher order pages to be free */
min >>= 1;
if (free_pages <= min)
return 0;
}
return 1;
}
zone_watermark_ok() 是一个辅助函数,在满足如下两个条件时返回 1:
- 除了被分配的页框外,内存管理区中至少还有
min个空闲页框(不包括保留的页框)。 - 除了被分配的页框外,在
order至少为o的块中,有大于等于min/ 2^o 个空闲页框。
阈值 min 的值由 mask. can_try_harder 和 gfp_high 确定:
mask可能是pages_min.pages_low和pages_high中的一个。- 若
gfp_high被置位,把么把mask除以2。 这种情况通常发生在__GFP_WAIT标志被置位时,即能从高端内存分配页框。 - 若
can_try_harder被置位,那么把mask再除以4。 这种情况通常发生在__GFP_WAIT标志被置位时,或者当前进程是一个位于进程上下文中(不在中断处理程序和可延迟函数中)且已经完成内存分配的实时进程。
__alloc_pages() 函数
mm/page_alloc.c:
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page * fastcall
__alloc_pages(unsigned int gfp_mask, unsigned int order,
struct zonelist *zonelist)
{
... // 详细流程见下
}
EXPORT_SYMBOL(__alloc_pages);
该函数的详细流程是:
准备工作。
const int wait = gfp_mask & __GFP_WAIT; struct zone **zones, *z; struct page *page; struct reclaim_state reclaim_state; struct task_struct *p = current; int i; int classzone_idx; int do_retry; int can_try_harder; int did_some_progress; might_sleep_if(wait); /* * The caller may dip into page reserves a bit more if the caller * cannot run direct reclaim, or is the caller has realtime scheduling * policy */ can_try_harder = (unlikely(rt_task(p)) && !in_interrupt()) || !wait; zones = zonelist->zones; /* the list of zones suitable for gfp_mask */ if (unlikely(zones[0] == NULL)) { /* Should this ever happen?? */ return NULL; } classzone_idx = zone_idx(zones[0]);第一次遍历存放管理区的数组(
zonelist),寻找有足够空闲内存的管理区。若能满足请求,跳转到第 15 步。restart: /* Go through the zonelist once, looking for a zone with enough free */ for (i = 0; (z = zones[i]) != NULL; i++) { if (!zone_watermark_ok(z, order, z->pages_low, classzone_idx, 0, 0)) continue; page = buffered_rmqueue(z, order, gfp_mask); if (page) goto got_pg; }来到这里,说明没足够的空闲内存。触发页框回收算法,这部分内容属于《深入理解 Linux 内核》中“回收页框”章节,这里不展开。
for (i = 0; (z = zones[i]) != NULL; i++) wakeup_kswapd(z, order);第二次遍历存放管理区的数组,但使用了较低的阈值(注意传递给
zone_watermark_ok()的参数不同)。若能满足请求,跳转到第 15 步。/* * Go through the zonelist again. Let __GFP_HIGH and allocations * coming from realtime tasks to go deeper into reserves */ for (i = 0; (z = zones[i]) != NULL; i++) { if (!zone_watermark_ok(z, order, z->pages_min, classzone_idx, can_try_harder, gfp_mask & __GFP_HIGH)) continue; page = buffered_rmqueue(z, order, gfp_mask); if (page) goto got_pg; }来到这里,说明系统没足够内存。如果内存分配请求的内核路径不是一个中断处理程序或一个可延迟函数,并且试图回收页框(
PF_MEMALLOC或TIF_MEMDIE标志被置位),那么进行第三次遍历,这次忽略阈值(不调用zone_watermark_ok())。这种情况下,允许内核控制路径耗用为内存不足预留的页(保留的页框池)。其实,PF_MEMALLOC表示该进程当前正在执行“内存规整(memory compaction)”或“直接回收(direct reclaim)”,而TIF_MEMDIE则表示该进程已经触发了内存不足清理(out-of-memory killer)并且正在尝试退出,以上这些操作都可能导致更多的内存页框被释放,因此只要有可能,请求就被满足。若能满足请求,跳转到第 15 步;反之,跳转到第 14 步。/* This allocation should allow future memory freeing. */ if (((p->flags & PF_MEMALLOC) || unlikely(test_thread_flag(TIF_MEMDIE))) && !in_interrupt()) { /* go through the zonelist yet again, ignoring mins */ for (i = 0; (z = zones[i]) != NULL; i++) { page = buffered_rmqueue(z, order, gfp_mask); if (page) goto got_pg; } goto nopage; }来到这里,必须阻塞当前进程才能满足请求(
__GFP_WAIT需要被置位)。否则,跳转到第 14 步。/* Atomic allocations - we can't balance anything */ if (!wait) goto nopage;来到这里,说明进程能够被阻塞,调用
cond_resched()检查是否有其它进程需要 CPU。rebalance: cond_resched();设置
PF_MEMALLOC标志,表示进程已经准备好执行内存回收。/* We now go into synchronous reclaim */ p->flags |= PF_MEMALLOC;将
reclaim_state存入current->reclaim_state。reclaim_state.reclaimed_slab = 0; p->reclaim_state = &reclaim_state;调用
try_to_free_pages()来回收页框,这部分内容属于《深入理解 Linux 内核》中“回收页框”章节,这里不展开。该函数可能阻塞当前进程,一旦函数返回,重设PF_MEMALLOC标志并再次调用cond_resched()。did_some_progress = try_to_free_pages(zones, gfp_mask, order); p->reclaim_state = NULL; p->flags &= ~PF_MEMALLOC; cond_resched();如果已经释放了一些页框,那么按第 4 步的方式再次遍历存放内存管理区的数组。若能满足请求,跳转到第 15 步。如果分配请求不能被满足,
__GFP_NORETRY(分配失败时不重复分配)被清除且__GFP_FS(可以启动文件系统 I/O)被置位,那么再次遍历存放内存管理区的数组(注意传递给zone_watermark_ok()的参数不同)。若能满足请求,跳转到第 15 步;反之,说明内存耗尽,通过调用out_of_memory()(该函数位于mm/oom_kill.c)杀死一个进程,来保证系统不崩溃,然后转到第 2 步。这次遍历的阈值比之前的要高,因此很容易失败,只有在另一个内核控制路径已经通过杀死了一个进程来回收了它的内存的时候,才会成功,但这种情况下,确实避免了两个无辜的进程(而不是一个)被杀死。if (likely(did_some_progress)) { /* * Go through the zonelist yet one more time, keep * very high watermark here, this is only to catch * a parallel oom killing, we must fail if we're still * under heavy pressure. */ for (i = 0; (z = zones[i]) != NULL; i++) { if (!zone_watermark_ok(z, order, z->pages_min, classzone_idx, can_try_harder, gfp_mask & __GFP_HIGH)) continue; page = buffered_rmqueue(z, order, gfp_mask); if (page) goto got_pg; } } else if ((gfp_mask & __GFP_FS) && !(gfp_mask & __GFP_NORETRY)) { /* * Go through the zonelist yet one more time, keep * very high watermark here, this is only to catch * a parallel oom killing, we must fail if we're still * under heavy pressure. */ for (i = 0; (z = zones[i]) != NULL; i++) { if (!zone_watermark_ok(z, order, z->pages_high, classzone_idx, 0, 0)) continue; page = buffered_rmqueue(z, order, gfp_mask); if (page) goto got_pg; } out_of_memory(gfp_mask); goto restart; }如果
order <= 3(和具体实现有关)或者__GFP_REPEAT被置位,设置do_retry。如果__GFP_NOFAIL被置位,设置do_retry。/* * Don't let big-order allocations loop unless the caller explicitly * requests that. Wait for some write requests to complete then retry. * * In this implementation, __GFP_REPEAT means __GFP_NOFAIL for order * <= 3, but that may not be true in other implementations. */ do_retry = 0; if (!(gfp_mask & __GFP_NORETRY)) { if ((order <= 3) || (gfp_mask & __GFP_REPEAT)) do_retry = 1; if (gfp_mask & __GFP_NOFAIL) do_retry = 1; }如果
do_retry被设置,调用blk_congestion_wait()使进程休眠一会(见 TODO),并跳转到第 7 步。if (do_retry) { blk_congestion_wait(WRITE, HZ/50); goto rebalance; }来到这里,说明请求不能被满足,返回
NULL。nopage: if (!(gfp_mask & __GFP_NOWARN) && printk_ratelimit()) { printk(KERN_WARNING "%s: page allocation failure." " order:%d, mode:0x%x\n", p->comm, order, gfp_mask); dump_stack(); } return NULL;来到这里,说明请求能被满足,调用
zone_statistics()完成一些数据统计工作 (主要针对 NUMA),然后返回第一个被分配的页框的页描述符。got_pg: zone_statistics(zonelist, z); return page;
释放内存
__free_pages() 函数比较简单,直接贴代码。
mm/page_alloc.c:
void __free_pages_ok(struct page *page, unsigned int order)
{
LIST_HEAD(list);
int i;
arch_free_page(page, order);
mod_page_state(pgfree, 1 << order);
#ifndef CONFIG_MMU
if (order > 0)
for (i = 1 ; i < (1 << order) ; ++i)
__put_page(page + i);
#endif
for (i = 0 ; i < (1 << order) ; ++i)
free_pages_check(__FUNCTION__, page + i);
list_add(&page->lru, &list);
kernel_map_pages(page, 1<<order, 0);
free_pages_bulk(page_zone(page), 1, &list, order);
}
fastcall void __free_pages(struct page *page, unsigned int order)
{
if (!PageReserved(page) && put_page_testzero(page)) {
if (order == 0)
free_hot_page(page);
else
__free_pages_ok(page, order);
}
}
EXPORT_SYMBOL(__free_pages);
include/linux/mm.h:
/*
* Drop a ref, return true if the logical refcount fell to zero (the page has
* no users)
*/
#define put_page_testzero(p) \
({ \
BUG_ON(page_count(p) == 0); \
atomic_add_negative(-1, &(p)->_count); \
})
很多函数涉及伙伴系统和 per-CPU 页框高速缓存,这里就不展开了。
内存池
内存池允许一个内核成分,如块设备子系统,仅在内存不足的紧急情况下分配一些动态内存来使用。
注意内存池与保留的页框池(见保留的页框池)的区别。保留的页框池是用于满足中断处理程序或内部临界区发出的原子分配请求的;而内存池是动态内存的储备,只能被特定的内核成分(池的拥有者)使用。
拥有者通常不使用内存池的储备(而是从普通内存中分配),如果动态内存变得极其稀有以至于所有普通内存分配请求都失败的话,那么内核成分就能调用特地的内存池函数提取储备得到所需的内存。当然,这已经是最后的解决手段了。