
FreeFlyingSheep
Monday, April 26, 2021 | 8 分钟
内存管理初始化
Linux 内核学习笔记系列,内存管理部分,简单介绍内存管理初始化。
内存管理初始化简介
体系结构相关的部分只考虑 x86-32 架构。
初始化相关的操作总是从 start_kernel() 开始看起,与内存管理初始化相关的流程如下(图片来源于 PLKA):
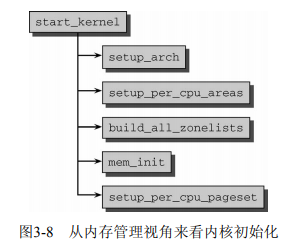
start_kernel() 函数位于 init/main.c。
setup_arch()
setup_arch() 的流程如下(图片来源于 PLKA):
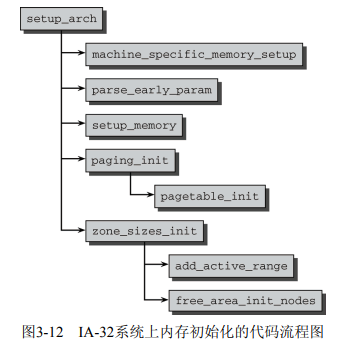
setup_arch() 函数位于 arch/x86/kernel/setup.c。
这部分内容在内核中经常被重构,导致不同内核版本间差异较大。事实上,我所查看的源码版本虽然与 PLKA 指示的内核版本很接近,但图中的很多函数已经重构了。
machine_specific_memory_setup()
直接搜索找不到 machine_specific_memory_setup() 函数,该函数应该已经被重构,推测功能接近的函数为 setup_memory_map()。
x86-32 架构使用 BIOS 的 e820 功能来探测物理内存。
在 arch/x86/kernel/e820.c 中,定义了 char *__init default_machine_specific_memory_setup(void) 函数,这个函数在 arch/x86/kernel/x86_init.c 中被赋值给了 resources.memory_setup:
/*
* The platform setup functions are preset with the default functions
* for standard PC hardware.
*/
struct x86_init_ops x86_init __initdata = {
.resources = {
.probe_roms = x86_init_noop,
.reserve_resources = reserve_standard_io_resources,
.memory_setup = default_machine_specific_memory_setup,
},
...
之后在 setup_memory_map() 函数中被调用,而 setup_memory_map() 函数在 setup_arch() 中被调用。
arch/x86/kernel/e820.c:
void __init setup_memory_map(void)
{
char *who;
who = x86_init.resources.memory_setup();
memcpy(&e820_saved, &e820, sizeof(struct e820map));
printk(KERN_INFO "BIOS-provided physical RAM map:\n");
e820_print_map(who);
}
parse_early_param()
内核的命令行参数可能有与内存管理相关的选项,因此把 parse_early_param() 也视为内存管理初始化的一部分。
parse_early_param() 函数首先在 setup_arch() 函数中调用,虽然之后 start_kernel() 也会调用它。该函数的定义位于 init/main.c:
/* Arch code calls this early on, or if not, just before other parsing. */
void __init parse_early_param(void)
{
static __initdata int done = 0;
static __initdata char tmp_cmdline[COMMAND_LINE_SIZE];
if (done)
return;
/* All fall through to do_early_param. */
strlcpy(tmp_cmdline, boot_command_line, COMMAND_LINE_SIZE);
parse_early_options(tmp_cmdline);
done = 1;
}
该函数调用 init/main.c 中的 parse_early_options(),通过 parse_args() 函数处理(parse_args() 细节不展开了):
void __init parse_early_options(char *cmdline)
{
parse_args("early options", cmdline, NULL, 0, do_early_param);
}
setup_memory()
该函数在当前版本内核源码里已经找不到了,推测改名为了 initmem_init() 和 ,UMA 和 NUMA 版本分别放置于 arch/x86/mm/init_32.c 和 arch/x86/mm/numa_32.c。
arch/x86/mm/init_32.c:
#ifndef CONFIG_NEED_MULTIPLE_NODES
void __init initmem_init(unsigned long start_pfn, unsigned long end_pfn,
int acpi, int k8)
{
#ifdef CONFIG_HIGHMEM
highstart_pfn = highend_pfn = max_pfn;
if (max_pfn > max_low_pfn)
highstart_pfn = max_low_pfn;
e820_register_active_regions(0, 0, highend_pfn);
sparse_memory_present_with_active_regions(0);
printk(KERN_NOTICE "%ldMB HIGHMEM available.\n",
pages_to_mb(highend_pfn - highstart_pfn));
num_physpages = highend_pfn;
high_memory = (void *) __va(highstart_pfn * PAGE_SIZE - 1) + 1;
#else
e820_register_active_regions(0, 0, max_low_pfn);
sparse_memory_present_with_active_regions(0);
num_physpages = max_low_pfn;
high_memory = (void *) __va(max_low_pfn * PAGE_SIZE - 1) + 1;
#endif
#ifdef CONFIG_FLATMEM
max_mapnr = num_physpages;
#endif
__vmalloc_start_set = true;
printk(KERN_NOTICE "%ldMB LOWMEM available.\n",
pages_to_mb(max_low_pfn));
setup_bootmem_allocator();
}
#endif /* !CONFIG_NEED_MULTIPLE_NODES */
arch/x86/mm/numa_32.c:
void __init initmem_init(unsigned long start_pfn, unsigned long end_pfn,
int acpi, int k8)
{
int nid;
long kva_target_pfn;
/*
* When mapping a NUMA machine we allocate the node_mem_map arrays
* from node local memory. They are then mapped directly into KVA
* between zone normal and vmalloc space. Calculate the size of
* this space and use it to adjust the boundary between ZONE_NORMAL
* and ZONE_HIGHMEM.
*/
get_memcfg_numa();
kva_pages = roundup(calculate_numa_remap_pages(), PTRS_PER_PTE);
kva_target_pfn = round_down(max_low_pfn - kva_pages, PTRS_PER_PTE);
do {
kva_start_pfn = find_e820_area(kva_target_pfn<<PAGE_SHIFT,
max_low_pfn<<PAGE_SHIFT,
kva_pages<<PAGE_SHIFT,
PTRS_PER_PTE<<PAGE_SHIFT) >> PAGE_SHIFT;
kva_target_pfn -= PTRS_PER_PTE;
} while (kva_start_pfn == -1UL && kva_target_pfn > min_low_pfn);
if (kva_start_pfn == -1UL)
panic("Can not get kva space\n");
printk(KERN_INFO "kva_start_pfn ~ %lx max_low_pfn ~ %lx\n",
kva_start_pfn, max_low_pfn);
printk(KERN_INFO "max_pfn = %lx\n", max_pfn);
/* avoid clash with initrd */
reserve_early(kva_start_pfn<<PAGE_SHIFT,
(kva_start_pfn + kva_pages)<<PAGE_SHIFT,
"KVA PG");
#ifdef CONFIG_HIGHMEM
highstart_pfn = highend_pfn = max_pfn;
if (max_pfn > max_low_pfn)
highstart_pfn = max_low_pfn;
printk(KERN_NOTICE "%ldMB HIGHMEM available.\n",
pages_to_mb(highend_pfn - highstart_pfn));
num_physpages = highend_pfn;
high_memory = (void *) __va(highstart_pfn * PAGE_SIZE - 1) + 1;
#else
num_physpages = max_low_pfn;
high_memory = (void *) __va(max_low_pfn * PAGE_SIZE - 1) + 1;
#endif
printk(KERN_NOTICE "%ldMB LOWMEM available.\n",
pages_to_mb(max_low_pfn));
printk(KERN_DEBUG "max_low_pfn = %lx, highstart_pfn = %lx\n",
max_low_pfn, highstart_pfn);
printk(KERN_DEBUG "Low memory ends at vaddr %08lx\n",
(ulong) pfn_to_kaddr(max_low_pfn));
for_each_online_node(nid) {
init_remap_allocator(nid);
allocate_pgdat(nid);
}
remap_numa_kva();
printk(KERN_DEBUG "High memory starts at vaddr %08lx\n",
(ulong) pfn_to_kaddr(highstart_pfn));
for_each_online_node(nid)
propagate_e820_map_node(nid);
for_each_online_node(nid) {
memset(NODE_DATA(nid), 0, sizeof(struct pglist_data));
NODE_DATA(nid)->node_id = nid;
#ifndef CONFIG_NO_BOOTMEM
NODE_DATA(nid)->bdata = &bootmem_node_data[nid];
#endif
}
setup_bootmem_allocator();
}
该函数主要用于确定物理页的数目,然后初始化 bootmem 分配器,bootmem 分配器的具体细节见 bootmem 分配器。
paging_init()
paging_init() 函数位于 arch/x86/mm/init_32.c:
/*
* paging_init() sets up the page tables - note that the first 8MB are
* already mapped by head.S.
*
* This routines also unmaps the page at virtual kernel address 0, so
* that we can trap those pesky NULL-reference errors in the kernel.
*/
void __init paging_init(void)
{
pagetable_init();
__flush_tlb_all();
kmap_init();
/*
* NOTE: at this point the bootmem allocator is fully available.
*/
sparse_init();
zone_sizes_init();
}
该函数会调用 pagetable_init 来确保直接映射的地址空间的物理内存被初始化:
#ifdef CONFIG_HIGHMEM
static void __init permanent_kmaps_init(pgd_t *pgd_base)
{
unsigned long vaddr;
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
vaddr = PKMAP_BASE;
page_table_range_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base);
pgd = swapper_pg_dir + pgd_index(vaddr);
pud = pud_offset(pgd, vaddr);
pmd = pmd_offset(pud, vaddr);
pte = pte_offset_kernel(pmd, vaddr);
pkmap_page_table = pte;
}
#else
static inline void permanent_kmaps_init(pgd_t *pgd_base)
{
}
#endif /* CONFIG_HIGHMEM */
static void __init pagetable_init(void)
{
pgd_t *pgd_base = swapper_pg_dir;
permanent_kmaps_init(pgd_base);
}
这部分的细节太多,我不打算深入看了。
zone_sizes_init()
可以看到,在当前版本,该函数的调用者变成了 paging_init() 函数,而非 setup_arch() 函数。
static void __init zone_sizes_init(void)
{
unsigned long max_zone_pfns[MAX_NR_ZONES];
memset(max_zone_pfns, 0, sizeof(max_zone_pfns));
max_zone_pfns[ZONE_DMA] =
virt_to_phys((char *)MAX_DMA_ADDRESS) >> PAGE_SHIFT;
max_zone_pfns[ZONE_NORMAL] = max_low_pfn;
#ifdef CONFIG_HIGHMEM
max_zone_pfns[ZONE_HIGHMEM] = highend_pfn;
#endif
free_area_init_nodes(max_zone_pfns);
}
add_active_range() 对可用的物理内存建立一个相对简单的列表。但该函数已经不在 zone_sizes_init() 中被调用了,搜索后发现该函数在 initmem_init() 中已经被调用了,函数调用链是 initmem_init() -> e820_register_active_regions() -> add_active_range()。
free_area_init_nodes() 它使用之前建立的列表来建立完备的内核数据结构。该函数是体系结构无关的,定义于 mm/page_alloc.c,这里不展开。
setup_per_cpu_areas()
setup_per_cpu_areas() 函数位于 arch/x86/kernel/setup_percpu.c,用于初始化 per-CPU 高速缓存。
void __init setup_per_cpu_areas(void)
{
unsigned int cpu;
unsigned long delta;
int rc;
pr_info("NR_CPUS:%d nr_cpumask_bits:%d nr_cpu_ids:%d nr_node_ids:%d\n",
NR_CPUS, nr_cpumask_bits, nr_cpu_ids, nr_node_ids);
/*
* Allocate percpu area. Embedding allocator is our favorite;
* however, on NUMA configurations, it can result in very
* sparse unit mapping and vmalloc area isn't spacious enough
* on 32bit. Use page in that case.
*/
#ifdef CONFIG_X86_32
if (pcpu_chosen_fc == PCPU_FC_AUTO && pcpu_need_numa())
pcpu_chosen_fc = PCPU_FC_PAGE;
#endif
rc = -EINVAL;
if (pcpu_chosen_fc != PCPU_FC_PAGE) {
const size_t atom_size = cpu_has_pse ? PMD_SIZE : PAGE_SIZE;
const size_t dyn_size = PERCPU_MODULE_RESERVE +
PERCPU_DYNAMIC_RESERVE - PERCPU_FIRST_CHUNK_RESERVE;
rc = pcpu_embed_first_chunk(PERCPU_FIRST_CHUNK_RESERVE,
dyn_size, atom_size,
pcpu_cpu_distance,
pcpu_fc_alloc, pcpu_fc_free);
if (rc < 0)
pr_warning("%s allocator failed (%d), falling back to page size\n",
pcpu_fc_names[pcpu_chosen_fc], rc);
}
if (rc < 0)
rc = pcpu_page_first_chunk(PERCPU_FIRST_CHUNK_RESERVE,
pcpu_fc_alloc, pcpu_fc_free,
pcpup_populate_pte);
if (rc < 0)
panic("cannot initialize percpu area (err=%d)", rc);
/* alrighty, percpu areas up and running */
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu) {
per_cpu_offset(cpu) = delta + pcpu_unit_offsets[cpu];
per_cpu(this_cpu_off, cpu) = per_cpu_offset(cpu);
per_cpu(cpu_number, cpu) = cpu;
setup_percpu_segment(cpu);
setup_stack_canary_segment(cpu);
/*
* Copy data used in early init routines from the
* initial arrays to the per cpu data areas. These
* arrays then become expendable and the *_early_ptr's
* are zeroed indicating that the static arrays are
* gone.
*/
#ifdef CONFIG_X86_LOCAL_APIC
per_cpu(x86_cpu_to_apicid, cpu) =
early_per_cpu_map(x86_cpu_to_apicid, cpu);
per_cpu(x86_bios_cpu_apicid, cpu) =
early_per_cpu_map(x86_bios_cpu_apicid, cpu);
#endif
#ifdef CONFIG_X86_64
per_cpu(irq_stack_ptr, cpu) =
per_cpu(irq_stack_union.irq_stack, cpu) +
IRQ_STACK_SIZE - 64;
#ifdef CONFIG_NUMA
per_cpu(x86_cpu_to_node_map, cpu) =
early_per_cpu_map(x86_cpu_to_node_map, cpu);
#endif
#endif
/*
* Up to this point, the boot CPU has been using .data.init
* area. Reload any changed state for the boot CPU.
*/
if (cpu == boot_cpu_id)
switch_to_new_gdt(cpu);
}
/* indicate the early static arrays will soon be gone */
#ifdef CONFIG_X86_LOCAL_APIC
early_per_cpu_ptr(x86_cpu_to_apicid) = NULL;
early_per_cpu_ptr(x86_bios_cpu_apicid) = NULL;
#endif
#if defined(CONFIG_X86_64) && defined(CONFIG_NUMA)
early_per_cpu_ptr(x86_cpu_to_node_map) = NULL;
#endif
#if defined(CONFIG_X86_64) && defined(CONFIG_NUMA)
/*
* make sure boot cpu node_number is right, when boot cpu is on the
* node that doesn't have mem installed
*/
per_cpu(node_number, boot_cpu_id) = cpu_to_node(boot_cpu_id);
#endif
/* Setup node to cpumask map */
setup_node_to_cpumask_map();
/* Setup cpu initialized, callin, callout masks */
setup_cpu_local_masks();
}
build_all_zonelists()
build_all_zonelists() 函数位于 mm/page_alloc.c,用于初始化结点和内存区域。
该函数和其调用的相关函数定义如下:
static void build_zonelists(pg_data_t *pgdat)
{
int j, node, load;
enum zone_type i;
nodemask_t used_mask;
int local_node, prev_node;
struct zonelist *zonelist;
int order = current_zonelist_order;
/* initialize zonelists */
for (i = 0; i < MAX_ZONELISTS; i++) {
zonelist = pgdat->node_zonelists + i;
zonelist->_zonerefs[0].zone = NULL;
zonelist->_zonerefs[0].zone_idx = 0;
}
/* NUMA-aware ordering of nodes */
local_node = pgdat->node_id;
load = nr_online_nodes;
prev_node = local_node;
nodes_clear(used_mask);
memset(node_order, 0, sizeof(node_order));
j = 0;
while ((node = find_next_best_node(local_node, &used_mask)) >= 0) {
int distance = node_distance(local_node, node);
/*
* If another node is sufficiently far away then it is better
* to reclaim pages in a zone before going off node.
*/
if (distance > RECLAIM_DISTANCE)
zone_reclaim_mode = 1;
/*
* We don't want to pressure a particular node.
* So adding penalty to the first node in same
* distance group to make it round-robin.
*/
if (distance != node_distance(local_node, prev_node))
node_load[node] = load;
prev_node = node;
load--;
if (order == ZONELIST_ORDER_NODE)
build_zonelists_in_node_order(pgdat, node);
else
node_order[j++] = node; /* remember order */
}
if (order == ZONELIST_ORDER_ZONE) {
/* calculate node order -- i.e., DMA last! */
build_zonelists_in_zone_order(pgdat, j);
}
build_thisnode_zonelists(pgdat);
}
/* return values int ....just for stop_machine() */
static int __build_all_zonelists(void *dummy)
{
int nid;
int cpu;
#ifdef CONFIG_NUMA
memset(node_load, 0, sizeof(node_load));
#endif
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
build_zonelists(pgdat);
build_zonelist_cache(pgdat);
}
/*
* Initialize the boot_pagesets that are going to be used
* for bootstrapping processors. The real pagesets for
* each zone will be allocated later when the per cpu
* allocator is available.
*
* boot_pagesets are used also for bootstrapping offline
* cpus if the system is already booted because the pagesets
* are needed to initialize allocators on a specific cpu too.
* F.e. the percpu allocator needs the page allocator which
* needs the percpu allocator in order to allocate its pagesets
* (a chicken-egg dilemma).
*/
for_each_possible_cpu(cpu)
setup_pageset(&per_cpu(boot_pageset, cpu), 0);
return 0;
}
void build_all_zonelists(void)
{
set_zonelist_order();
if (system_state == SYSTEM_BOOTING) {
__build_all_zonelists(NULL);
mminit_verify_zonelist();
cpuset_init_current_mems_allowed();
} else {
/* we have to stop all cpus to guarantee there is no user
of zonelist */
stop_machine(__build_all_zonelists, NULL, NULL);
/* cpuset refresh routine should be here */
}
vm_total_pages = nr_free_pagecache_pages();
/*
* Disable grouping by mobility if the number of pages in the
* system is too low to allow the mechanism to work. It would be
* more accurate, but expensive to check per-zone. This check is
* made on memory-hotadd so a system can start with mobility
* disabled and enable it later
*/
if (vm_total_pages < (pageblock_nr_pages * MIGRATE_TYPES))
page_group_by_mobility_disabled = 1;
else
page_group_by_mobility_disabled = 0;
printk("Built %i zonelists in %s order, mobility grouping %s. "
"Total pages: %ld\n",
nr_online_nodes,
zonelist_order_name[current_zonelist_order],
page_group_by_mobility_disabled ? "off" : "on",
vm_total_pages);
#ifdef CONFIG_NUMA
printk("Policy zone: %s\n", zone_names[policy_zone]);
#endif
}
mm_init()
mm_init() 函数位于 init/main.c:
/*
* Set up kernel memory allocators
*/
static void __init mm_init(void)
{
/*
* page_cgroup requires countinous pages as memmap
* and it's bigger than MAX_ORDER unless SPARSEMEM.
*/
page_cgroup_init_flatmem();
mem_init();
kmem_cache_init();
pgtable_cache_init();
vmalloc_init();
}
mem_init() 函数用于停用 bootmem 分配器并迁移到实际的内存管理函数(见 bootmem 分配器),kmem_cache_init() 函数用于初始化 slab/slob/slub 分配器。
setup_per_cpu_pageset()
setup_per_cpu_pageset() 函数位于 mm/page_alloc.c,用于分配并初始化 pageset:
/*
* Allocate per cpu pagesets and initialize them.
* Before this call only boot pagesets were available.
* Boot pagesets will no longer be used by this processorr
* after setup_per_cpu_pageset().
*/
void __init setup_per_cpu_pageset(void)
{
struct zone *zone;
int cpu;
for_each_populated_zone(zone) {
zone->pageset = alloc_percpu(struct per_cpu_pageset);
for_each_possible_cpu(cpu) {
struct per_cpu_pageset *pcp = per_cpu_ptr(zone->pageset, cpu);
setup_pageset(pcp, zone_batchsize(zone));
if (percpu_pagelist_fraction)
setup_pagelist_highmark(pcp,
(zone->present_pages /
percpu_pagelist_fraction));
}
}
}