
FreeFlyingSheep
Thursday, July 23, 2020 | 9 分钟
slab 分配器
Linux 内核学习笔记系列,内存管理部分,简单介绍 slab 分配器。
slab 分配器简介
slab 分配器是为了解决内碎片问题而设计的。
slab 分配器算法的前提
- 所存放数据的类型可以影响内存区的分配方式。slab 分配器概念扩充了这种思想,并把内存区看作对象(object),这些对象由一组数据结构和几个叫构造和析构的函数(方法)组成。前者初始化内存区,后者回收内存区。
- 内核函数倾向于反复请求同一类型的内存区。
- 对内存区的请求可以根据它们发生的频率分类。
- 在引入的对象大小不是几何分布(数据结构的起始物理地址不是 2 的幂(的情况下,可以借助处理器的硬件高速缓存。
- 硬件高速缓存的高性能会限制对伙伴系统分配器的调用,因为对伙伴系统的每次调用都“弄脏”硬件高速缓存,所以增加了内存的平均访问时间。内核函数对硬件高速缓存的影响就是所谓的函数“足迹(footprint)”,其定义为函数结束时重写硬件高速缓存的百分比。大“足迹”的函数的执行使硬件高速缓存填满了无用信息,导致之后执行代码的速度变慢。
slab 分配器算法的设计思想
- 频繁使用的数据结构也会频繁分配和释放,因此应当缓存它们。
- 频繁分配和回收必然会导致内存碎片(难以找到大块连续的可用内存)。空闲链表的缓存应该连续存放,因为已经释放的数据结构又会放回空闲链表,所以不会导致碎片。
- 回收的对象可以立即投入下一次分配,因此对于频繁的分配和释放,空闲链表能提高性能。
- 如果分配器知道对象的大小、页大小和总硬件高速缓存大小,它能做出更明智的决策。
- 如果让部分缓存专属于某个处理器,那么分配和释放就可以在不加 SMP 锁的情况下进行。
- 如果分配器是与 NUMA 相关的,它就可以从相同的内存结点为请求者进行分配。
- 对存放的对象进行着色(color),以防多个对象映射到相同的硬件高速缓存行(cache line)。
slab 分配器的组成
包含高速缓存(cache)的主内存区域被划分为多个 slab,每个 slab 由一个或多个连续的页框组成,这些页框既包含已分配的对象(object),也包含空闲的对象。
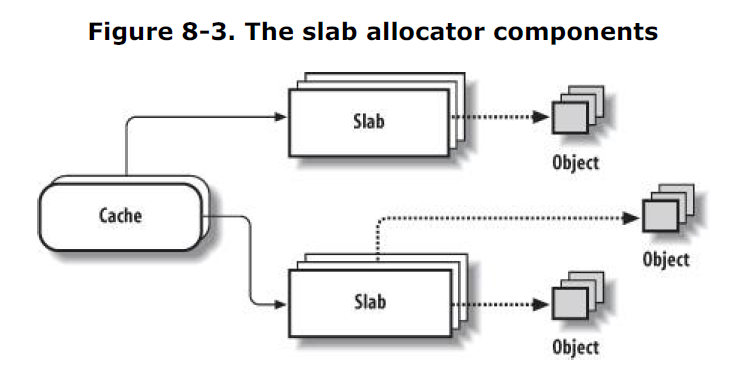
slab 分配器相关的描述符
高速缓存描述符
include/linux/slab.h:
/*
* The slab lists of all objects.
* Hopefully reduce the internal fragmentation
* NUMA: The spinlock could be moved from the kmem_cache_t
* into this structure, too. Figure out what causes
* fewer cross-node spinlock operations.
*/
struct kmem_list3 {
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects;
int free_touched;
unsigned long next_reap;
struct array_cache *shared;
};
/*
* kmem_cache_t
*
* manages a cache.
*/
struct kmem_cache_s {
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];
unsigned int batchcount;
unsigned int limit;
/* 2) touched by every alloc & free from the backend */
struct kmem_list3 lists;
/* NUMA: kmem_3list_t *nodelists[MAX_NUMNODES] */
unsigned int objsize;
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
unsigned int free_limit; /* upper limit of objects in the lists */
spinlock_t spinlock;
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
unsigned int gfpflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
unsigned int colour_next; /* cache colouring */
kmem_cache_t *slabp_cache;
unsigned int slab_size;
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *, kmem_cache_t *, unsigned long);
/* de-constructor func */
void (*dtor)(void *, kmem_cache_t *, unsigned long);
/* 4) cache creation/removal */
const char *name;
struct list_head next;
/* 5) statistics */
...
};
typedef struct kmem_cache_s kmem_cache_t;
slab 描述符
mm/slab.c:
/*
* struct slab
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/
struct slab {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
};
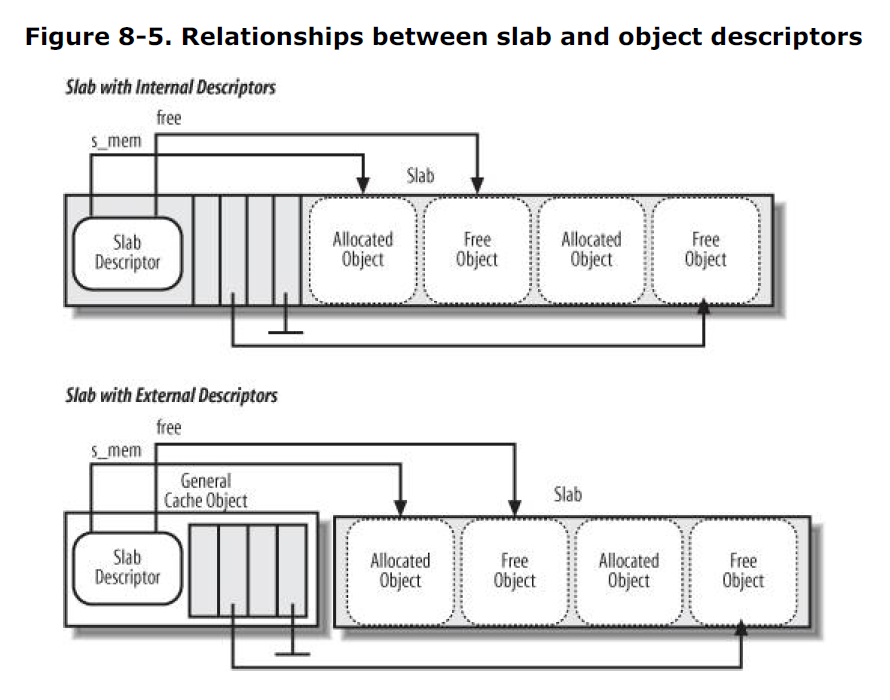
对象描述符
每个对象都有一个类型为 kmem_bufctl_t 的描述符,该描述符定义于 include/asm-xx/types.h (xx 代表相应体系结构),是一个无符号整型。
slab 的对象描述符也可以用两种方式存放:
- 外部对象描述符:存放在 slab 外部,位于高速缓存描述符
slabp_cache字段指向的一个普通高速缓存中,内存区大小取决于在 slab 中所存放的对象个数(高速缓存描述符的num字段)。 - 内部对象描述符:存放在 slab 内部,正好位于描述符所描述的对象之前。
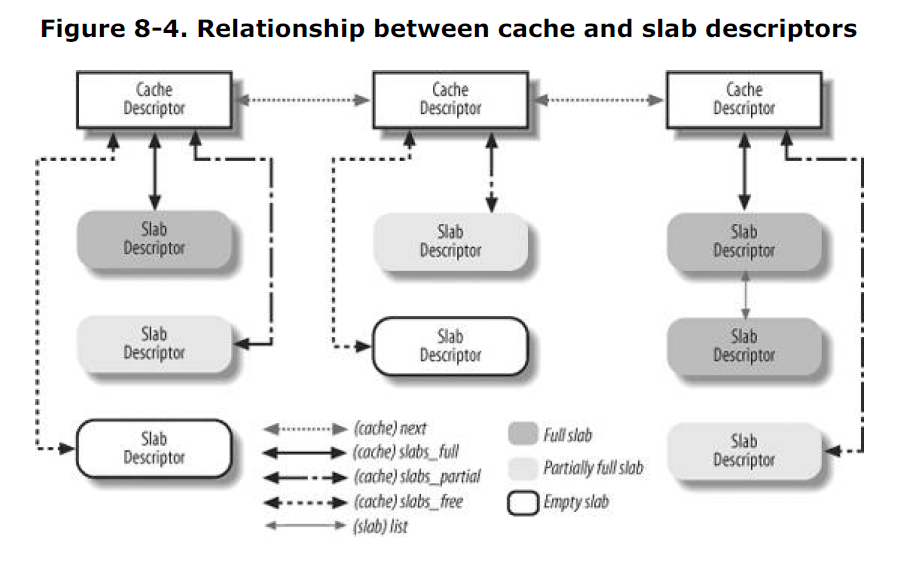
各描述符之间的关系
高速缓存描述符与 slab 描述符的关系如下:
slab 描述符与对象描述符的关系如下:
普通高速缓存和专用高速缓存
高速缓存被分为普通和专用两种,普通高速缓存只由 slab 分配器用于自己的目的,而专用高速缓存由内核的其余部分使用。
普通高速缓存
第一个高速缓存叫 kmem_cache,包含在 cache_cache 中。
mm/slab.c:
/* internal cache of cache description objs */
static kmem_cache_t cache_cache = {
.lists = LIST3_INIT(cache_cache.lists),
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.objsize = sizeof(kmem_cache_t),
.flags = SLAB_NO_REAP,
.spinlock = SPIN_LOCK_UNLOCKED,
.name = "kmem_cache",
#if DEBUG
.reallen = sizeof(kmem_cache_t),
#endif
};
另外的高速缓存包含用作普通用途的内存区,内存范围一般包括 13 个几何分布的内存区,大小分别为 32、64、128、256、512、1024、2048、4096、8192、16384、32768、65536 和 131072 字节。 malloc_size 数组的元素指向 26 个高速缓存描述符,因为每个内存区都包含两个高速缓存,一个用于 ISA DMA 分配,另一个用于常规分配。
mm/slab.c:
/* These are the default caches for kmalloc. Custom caches can have other sizes. */
struct cache_sizes malloc_sizes[] = {
#define CACHE(x) { .cs_size = (x) },
#include <linux/kmalloc_sizes.h>
{ 0, }
#undef CACHE
};
EXPORT_SYMBOL(malloc_sizes);
include/linux/kmalloc_sizes.h:
#if (PAGE_SIZE == 4096)
CACHE(32)
#endif
CACHE(64)
#if L1_CACHE_BYTES < 64
CACHE(96)
#endif
CACHE(128)
#if L1_CACHE_BYTES < 128
CACHE(192)
#endif
CACHE(256)
CACHE(512)
CACHE(1024)
CACHE(2048)
CACHE(4096)
CACHE(8192)
CACHE(16384)
CACHE(32768)
CACHE(65536)
CACHE(131072)
#ifndef CONFIG_MMU
CACHE(262144)
CACHE(524288)
CACHE(1048576)
#ifdef CONFIG_LARGE_ALLOCS
CACHE(2097152)
CACHE(4194304)
CACHE(8388608)
CACHE(16777216)
CACHE(33554432)
#endif /* CONFIG_LARGE_ALLOCS */
#endif /* CONFIG_MMU */
在系统初始化期间调用位于 mm/slab.c 的 kmem_cache_init() 函数来建立普通高速缓存(书上还提到了 kmem_cache_sizes_init() 函数,我并没找到这个函数,我查了一下较早版本的代码,目前版本该函数似乎已经被合并到了 kmem_cache_init() 函数中)。这个函数的代码太长了,我没有细看,先不展开了。
专用高速缓存
专用高速缓存由位于 mm/slab.c 的 kmem_cache_create() 函数创建。同样,这个函数的代码太长了,我没有细看,先不展开了。
slab 分配器与分区页框分配器
向页框分配器请求页框
mm/slab.c:
/*
* Interface to system's page allocator. No need to hold the cache-lock.
*
* If we requested dmaable memory, we will get it. Even if we
* did not request dmaable memory, we might get it, but that
* would be relatively rare and ignorable.
*/
static void *kmem_getpages(kmem_cache_t *cachep, int flags, int nodeid)
{
struct page *page;
void *addr;
int i;
flags |= cachep->gfpflags;
if (likely(nodeid == -1)) {
page = alloc_pages(flags, cachep->gfporder);
} else {
page = alloc_pages_node(nodeid, flags, cachep->gfporder);
}
if (!page)
return NULL;
addr = page_address(page);
i = (1 << cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_add(i, &slab_reclaim_pages);
add_page_state(nr_slab, i);
while (i--) {
SetPageSlab(page);
page++;
}
return addr;
}
释放分配给 slab 的页框
mm/slab.c:
/*
* Interface to system's page release.
*/
static void kmem_freepages(kmem_cache_t *cachep, void *addr)
{
unsigned long i = (1<<cachep->gfporder);
struct page *page = virt_to_page(addr);
const unsigned long nr_freed = i;
while (i--) {
if (!TestClearPageSlab(page))
BUG();
page++;
}
sub_page_state(nr_slab, nr_freed);
if (current->reclaim_state)
current->reclaim_state->reclaimed_slab += nr_freed;
free_pages((unsigned long)addr, cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_sub(1<<cachep->gfporder, &slab_reclaim_pages);
}
slab 分配器与高速缓存
给高速缓存分配 slab
mm/slab.c:
/*
* Grow (by 1) the number of slabs within a cache. This is called by
* kmem_cache_alloc() when there are no active objs left in a cache.
*/
static int cache_grow (kmem_cache_t * cachep, int flags, int nodeid)
{
struct slab *slabp;
void *objp;
size_t offset;
int local_flags;
unsigned long ctor_flags;
/* Be lazy and only check for valid flags here,
* keeping it out of the critical path in kmem_cache_alloc().
*/
if (flags & ~(SLAB_DMA|SLAB_LEVEL_MASK|SLAB_NO_GROW))
BUG();
if (flags & SLAB_NO_GROW)
return 0;
ctor_flags = SLAB_CTOR_CONSTRUCTOR;
local_flags = (flags & SLAB_LEVEL_MASK);
if (!(local_flags & __GFP_WAIT))
/*
* Not allowed to sleep. Need to tell a constructor about
* this - it might need to know...
*/
ctor_flags |= SLAB_CTOR_ATOMIC;
/* About to mess with non-constant members - lock. */
check_irq_off();
spin_lock(&cachep->spinlock);
/* Get colour for the slab, and cal the next value. */
offset = cachep->colour_next;
cachep->colour_next++;
if (cachep->colour_next >= cachep->colour)
cachep->colour_next = 0;
offset *= cachep->colour_off;
spin_unlock(&cachep->spinlock);
if (local_flags & __GFP_WAIT)
local_irq_enable();
/*
* The test for missing atomic flag is performed here, rather than
* the more obvious place, simply to reduce the critical path length
* in kmem_cache_alloc(). If a caller is seriously mis-behaving they
* will eventually be caught here (where it matters).
*/
kmem_flagcheck(cachep, flags);
/* Get mem for the objs. */
if (!(objp = kmem_getpages(cachep, flags, nodeid)))
goto failed;
/* Get slab management. */
if (!(slabp = alloc_slabmgmt(cachep, objp, offset, local_flags)))
goto opps1;
set_slab_attr(cachep, slabp, objp);
cache_init_objs(cachep, slabp, ctor_flags);
if (local_flags & __GFP_WAIT)
local_irq_disable();
check_irq_off();
spin_lock(&cachep->spinlock);
/* Make slab active. */
list_add_tail(&slabp->list, &(list3_data(cachep)->slabs_free));
STATS_INC_GROWN(cachep);
list3_data(cachep)->free_objects += cachep->num;
spin_unlock(&cachep->spinlock);
return 1;
opps1:
kmem_freepages(cachep, objp);
failed:
if (local_flags & __GFP_WAIT)
local_irq_disable();
return 0;
}
这个函数我没有细看,很多细节现在也看不懂,大致流程是首先调用 kmem_getpages() 获得一组页框来存放一个新的 slab,其次调用 alloc_slabmgmt() 获得一个新的 slab 描述符,然后调用 cache_init_jobs() 讲构造方法应用到新 slab 包含的所有对象上,最后调用 list_add_tail() 来将新得到的 slab 描述符 *slabp 添加到高速缓存描述符 *cachep 的全空 slab 链表的末端并更新高速缓存中的空闲对象计数器。
从高速缓存释放 slab
mm/slab.c:
/* Destroy all the objs in a slab, and release the mem back to the system.
* Before calling the slab must have been unlinked from the cache.
* The cache-lock is not held/needed.
*/
static void slab_destroy (kmem_cache_t *cachep, struct slab *slabp)
{
void *addr = slabp->s_mem - slabp->colouroff;
#if DEBUG
...
#else
if (cachep->dtor) {
int i;
for (i = 0; i < cachep->num; i++) {
void* objp = slabp->s_mem+cachep->objsize*i;
(cachep->dtor)(objp, cachep, 0);
}
}
#endif
if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) {
struct slab_rcu *slab_rcu;
slab_rcu = (struct slab_rcu *) slabp;
slab_rcu->cachep = cachep;
slab_rcu->addr = addr;
call_rcu(&slab_rcu->head, kmem_rcu_free);
} else {
kmem_freepages(cachep, addr);
if (OFF_SLAB(cachep))
kmem_cache_free(cachep->slabp_cache, slabp);
}
}
这个函数检查高速缓存是否为它的对象提供了析构方法,如果是,就用析构方法释放 slab 中的所有对象。接着调用 kmem_freepages() 把页框返回给伙伴系统。 关于设置了 SLAB_DESTROY_BY_RCU 标志的代码,见 TODO,这里不展开。
对齐内存中的对象
对齐对象由 kmem_cache_create() 函数完成,这里不展开。
slab 着色
简单概括,slab 着色就是对 slab 使用不同的颜色(不同的偏移量),尽量使得不同的对象的映射到不同的硬件高速缓存行上。着色相关的内容最终被摒弃了(slub 分配器),所以我不打算细看了。
空闲 slab 对象的本地高速缓存
类似 per-CPU 高速缓存,slab 分配器也包含每个 CPU 上的本地高速缓存,只在本地数组溢出时才涉及 slab 数据结构。高速缓存描述符的 array 字段就是一组指向 array_cache 数据结构的指针。本地高速缓存的描述符并不包含本地高速缓存本身的地址,它正好位于描述符之后。
mm/slab.c:
/*
* struct array_cache
*
* Per cpu structures
* Purpose:
* - LIFO ordering, to hand out cache-warm objects from _alloc
* - reduce the number of linked list operations
* - reduce spinlock operations
*
* The limit is stored in the per-cpu structure to reduce the data cache
* footprint.
*
*/
struct array_cache {
unsigned int avail; // 指向本地高速缓存中可使用对象的指针的个数,同时作为高速缓存中第一个空槽的下标
unsigned int limit; // 本地高速缓存中指针的最大个数
unsigned int batchcount; // 本地高速缓存重新填充或腾空时使用的大小
unsigned int touched; // 如果本地高速缓存最近已经被使用过,该标志为 1
};
分配和释放内存
分配 slab 对象
mm/slab.c:
static inline void ** ac_entry(struct array_cache *ac)
{
return (void**)(ac+1);
}
static inline struct array_cache *ac_data(kmem_cache_t *cachep)
{
return cachep->array[smp_processor_id()];
}
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*/
void * kmem_cache_alloc (kmem_cache_t *cachep, int flags)
{
return __cache_alloc(cachep, flags);
}
static inline void * __cache_alloc (kmem_cache_t *cachep, int flags)
{
unsigned long save_flags;
void* objp;
struct array_cache *ac;
cache_alloc_debugcheck_before(cachep, flags);
local_irq_save(save_flags);
ac = ac_data(cachep);
if (likely(ac->avail)) {
STATS_INC_ALLOCHIT(cachep);
ac->touched = 1;
objp = ac_entry(ac)[--ac->avail];
} else {
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags);
}
local_irq_restore(save_flags);
objp = cache_alloc_debugcheck_after(cachep, flags, objp, __builtin_return_address(0));
return objp;
}
首先试图从本地高速缓存获得一个空闲对象,如果没有,则调用 cache_alloc_refill() 函数重新填充本地高速缓存并获得一个空闲对象。cache_alloc_refill() 函数比较复杂,这里不展开。
释放 slab 对象
mm/slab.c:
/**
* kmem_cache_free - Deallocate an object
* @cachep: The cache the allocation was from.
* @objp: The previously allocated object.
*
* Free an object which was previously allocated from this
* cache.
*/
void kmem_cache_free (kmem_cache_t *cachep, void *objp)
{
unsigned long flags;
local_irq_save(flags);
__cache_free(cachep, objp);
local_irq_restore(flags);
}
/*
* __cache_free
* Release an obj back to its cache. If the obj has a constructed
* state, it must be in this state _before_ it is released.
*
* Called with disabled ints.
*/
static inline void __cache_free (kmem_cache_t *cachep, void* objp)
{
struct array_cache *ac = ac_data(cachep);
check_irq_off();
objp = cache_free_debugcheck(cachep, objp, __builtin_return_address(0));
if (likely(ac->avail < ac->limit)) {
STATS_INC_FREEHIT(cachep);
ac_entry(ac)[ac->avail++] = objp;
return;
} else {
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac);
ac_entry(ac)[ac->avail++] = objp;
}
}
首先检查本地高速缓存是否有空间给指向一个空闲对象的额外指针,如果有,该指针被加到本地高速缓存然后返回。否则,调用 cache_flusharray() 函数来清空本地高速缓存,再将指针加到本地高速缓存。 同样,cache_alloc_refill() 函数比较复杂,这里不展开。
分配通用对象
include/linux/slab.h:
static inline void *kmalloc(size_t size, int flags)
{
if (__builtin_constant_p(size)) {
int i = 0;
#define CACHE(x) \
if (size <= x) \
goto found; \
else \
i++;
#include "kmalloc_sizes.h"
#undef CACHE
{
extern void __you_cannot_kmalloc_that_much(void);
__you_cannot_kmalloc_that_much();
}
found:
return kmem_cache_alloc((flags & GFP_DMA) ?
malloc_sizes[i].cs_dmacachep :
malloc_sizes[i].cs_cachep, flags);
}
return __kmalloc(size, flags);
}
mm/slab.c:
/**
* kmalloc - allocate memory
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate.
*
* kmalloc is the normal method of allocating memory
* in the kernel.
*
* The @flags argument may be one of:
*
* %GFP_USER - Allocate memory on behalf of user. May sleep.
*
* %GFP_KERNEL - Allocate normal kernel ram. May sleep.
*
* %GFP_ATOMIC - Allocation will not sleep. Use inside interrupt handlers.
*
* Additionally, the %GFP_DMA flag may be set to indicate the memory
* must be suitable for DMA. This can mean different things on different
* platforms. For example, on i386, it means that the memory must come
* from the first 16MB.
*/
void * __kmalloc (size_t size, int flags)
{
struct cache_sizes *csizep = malloc_sizes;
for (; csizep->cs_size; csizep++) {
if (size > csizep->cs_size)
continue;
#if DEBUG
/* This happens if someone tries to call
* kmem_cache_create(), or kmalloc(), before
* the generic caches are initialized.
*/
BUG_ON(csizep->cs_cachep == NULL);
#endif
return __cache_alloc(flags & GFP_DMA ?
csizep->cs_dmacachep : csizep->cs_cachep, flags);
}
return NULL;
}
EXPORT_SYMBOL(__kmalloc);
释放通用对象
mm/slab.c:
/**
* kfree - free previously allocated memory
* @objp: pointer returned by kmalloc.
*
* Don't free memory not originally allocated by kmalloc()
* or you will run into trouble.
*/
void kfree (const void *objp)
{
kmem_cache_t *c;
unsigned long flags;
if (!objp)
return;
local_irq_save(flags);
kfree_debugcheck(objp);
c = GET_PAGE_CACHE(virt_to_page(objp));
__cache_free(c, (void*)objp);
local_irq_restore(flags);
}