
FreeFlyingSheep
Monday, July 13, 2020 | 2 分钟
MIPS 体系结构
根据 See MIPS Run (Second Edition)(中文版)整理。
流水线
MIPS 的流水线对程序员不完全透明,由此带来了延迟槽问题:
- 分支延迟槽:紧跟在分支指令后的那条指令将被执行,对于条件分支问题需要特别小心
- 加载延迟槽:紧跟在加载指令后的那条指令不能使用刚刚加载的数据
利用该特性,可以把其他有用的指令移到在延迟槽运行,但现在这些步骤通常由汇编器完成。
虚拟地址空间
32 位虚拟地址空间
32 位地址空间如下图所示:

下面只考虑带 MMU 的机器,其余情况需要查相应机器的手册。
kuseg(0x0000 0000-0x7FFF FFFF):作为用户态可用的地址,这些地址将被 MMU 转换,不能在 MMU 设置好前使用。部分文档也将这部分空间称为useg,但不建议这么称呼。kseg0(0x8000 0000-0x9FFF FFFF):映射低 512 MB 物理地址,用于存放操作系统核心。通过把最高位清零转换成物理地址,但会经过高速缓存,因此需要先初始化高速缓存。kseg1(0xA000 0000-0xBFFF FFFF):重复映射低 512 MB 物理地址,用于存取初始的程序的 ROM以及作为 I/O 寄存器。通过把最高 3 位清零转换成物理地址,不会经过告诉缓存,因此是系统重启时唯一能正常工作的地址空间。复位入口点存放于0xBFC0 0000,对应物理地址0x1FC0 0000.kseg2(0xC000 0000-0xFFFF FFFF):由操作系统内核使用,只能在内核态访问,需要被 MMU 转换,不能在 MMU 设置好前使用。
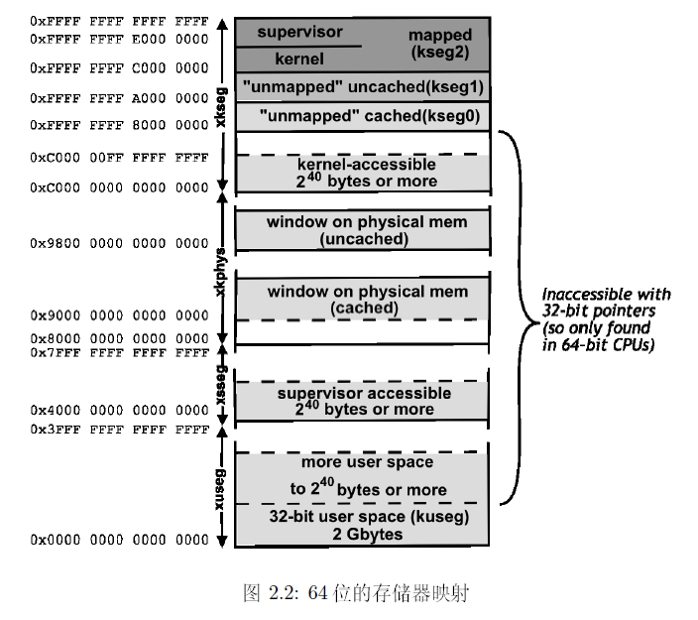
64 位虚拟地址空间
64 位地址空间被包在32 位地址空间中,如下图所示:
高速缓存的重影问题/别名(alias)问题
MIPS 的一级高速缓存通常采用虚拟地址生成索引,而采用物理地址作为标签,即 VIPT(Virtually Indexed Physically Tagged)。当页面大小 < 高速缓存索引范围时,就可能出现重影,如下图所示:

假设 32 位虚拟地址,使用 4K 的页面大小和 32K 四路组相联的高速缓存(8K 的高速缓存索引范围),且某个物理地址被同时映射到了连续的页——虚拟地址 0 和 4K 处。
当访问虚拟地址 0(0x0000 0000)处的数据时,该处的数据被加载到高速缓存的某个位置。之后访问虚拟地址 4K(0x0000 1000)处的数据,由于页面大小(4K,占 12 位)< 索引范围(8K,占 13 位),此时生成的索引与访问 0 处生成的索引不同(虚拟地址和物理地址的位 0-11 相同,位 12 不同),因此该数据被认为不在缓存中(未命中),然后被加载到高速缓存的另一个位置。现在在高速缓存中存在数据的两个副本,产生了重影。
MIPS 的二级缓存开始,通常采用物理地址作为索引和标签,即 PIPT(Physically Indexed Physically Tagged),因而不会产生重影问题。
异常
精确异常
在具备精确异常特性的 CPU 上,任何异常发生时,EPC 都指向异常受害指令。在该指令之前的指令全部执行完毕,之后的指令就好像没执行过一样(重新执行时要保证和没发生异常时的行为一样)。
在早期非精确异常的 CPU 上,乘除法运算不可停止(即使在异常发生时),乘除法指令和 mflo/mfhi 指令之间,必须插入两条非乘除法指令,来避免因改写 lo 和 hi 寄存器而得到错误的结果。
异常处理流程
当 MIPS CPU 决定处理异常时,会执行下列操作:
- 设置
EPC指向重新开始的地址。 - 设置
SR(EXL)位,强制 CPU 进入内核态并禁止中断; - 设置
Cause寄存器、BadVaddr(当地址异常时)、某些 MMU 寄存器(当存储系统异常时)。 - 从异常入口点取指,转到异常处理程序。
异常处理程序执行以下操作:
- 腾出空间完成引导。
- 查询
Cause(ExcCode)分派不同的异常。 - 分配栈空间并保存相应寄存器来构造异常处理环境(可以在分派不同的异常前完成这项工作)。
- 处理异常。
- 恢复保存的寄存器,修改SR寄存器来准备返回。
- 执行
eret指令(该指令会清楚SR(EXL)位并返回到EPC保存的地址)从异常返回。
汇编
分类
指令按功能可以分为 12 类:
- 空操作(No-op)
- 寄存器/寄存器传输(包括条件传送)
- 常数加载
- 算数/逻辑指令
- 整数乘法、除法和求余数
- 整数乘加
- 加载和存储
- 跳转、子程序调用和分支
- 断点和自陷
- CP0 功能(CPU 控制指令)
- 浮点
- 用户态下对底层特性的受限访问(
rdhwr和synci)
特殊指令及其用途
已经在其他章节介绍过的指令不再介绍,此处只列举部分常用的指令。
连锁加载/条件存储
指令 ll(load linked)和 sc(store conditional)提供“测试——设置”序列,在运行时不保证原子性,但仅当结果恰好是原子性的时候才能返回成功。
| 指令格式 | 含义 |
|---|---|
ll d,o(b) | d = memory[o + b],在 CPU 内设置不可见的连锁状态位,同时把加载地址保存在 LLAddr 寄存器中 |
sc t,o(b) | 检查从上次执行的 ll 指令开始以来的“读——改——写”序列是否能原子性的完成,若能,memory[o + b] = t; t = 1;若不能,t = 0 |
指令 sc 的失败有两种可能的原因:
- 发生了异常
- 多处理器下另一个 CPU 写入了附近的位置
以下是用该对指令实现“原子加一”操作的示例,对应 Linux 内核调用 atomic_inc(&mycount):
atomic_inc:
ll v0, 0(a0) # a0 指向 mycount
addu v0, 1
sc v0, 0(a0)
beq v0, zero, atomic_inc # 当 sc 失败时重试
nop
jr ra
nop
条件传送
| 指令格式 | 含义 |
|---|---|
movz d,s,t | if (!t) d = s |
数据存储防护
| 指令格式 | 含义 |
|---|---|
sync | 存取防护,所有在该指令前发起的存取操作的结果,在该指令后的任何存取操作中都能“见到” |
注意,该指令只保证后续指令能“见到”,但对存取操作和 sync 本身执行的相对时序没有保证,仅仅是把该指令和之后的指令存取操作分开,不能保证解决 CPU 的程序执行和外部写之间的时序关系问题。
用户态下对底层特性的受限访问
| 指令格式 | 含义 |
|---|---|
rdhwr | 读取硬件寄存器 |
synci | 为改写指令的程序做高速缓存管理 |